Editor's note: Alexis Cook, head of Udacity's deep reinforcement learning course, explained the concept of global average pooling (GAP) and demonstrated the ability of GAP-CNN trained for classification problems in target location.
In image classification tasks, the common choice of convolutional neural network (CNN) architecture is repeated convolution modules (convolutional layer plus pooling layer), followed by two or more dense layers (fully connected layers). Finally, the dense layer uses the softmax activation function, and each node corresponds to a category.
For example, the architecture of VGG-16:
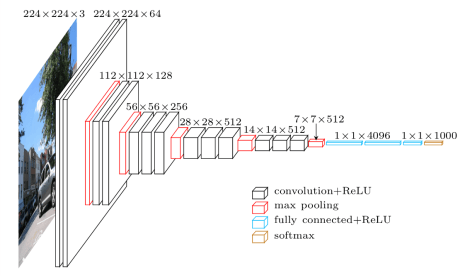
Translator's Note: In the above figure, the black is the convolutional layer (ReLU activation), the red is the maximum pooling layer, the blue is the fully connected layer (ReLU activation), and the gold is the softmax layer.
Run the following code to get a list of the network layers of the VGG-16 model: (Translator's Note: Keras needs to be installed)
python -c'from keras.applications.vgg16 import VGG16; VGG16().summary()'
The output is:
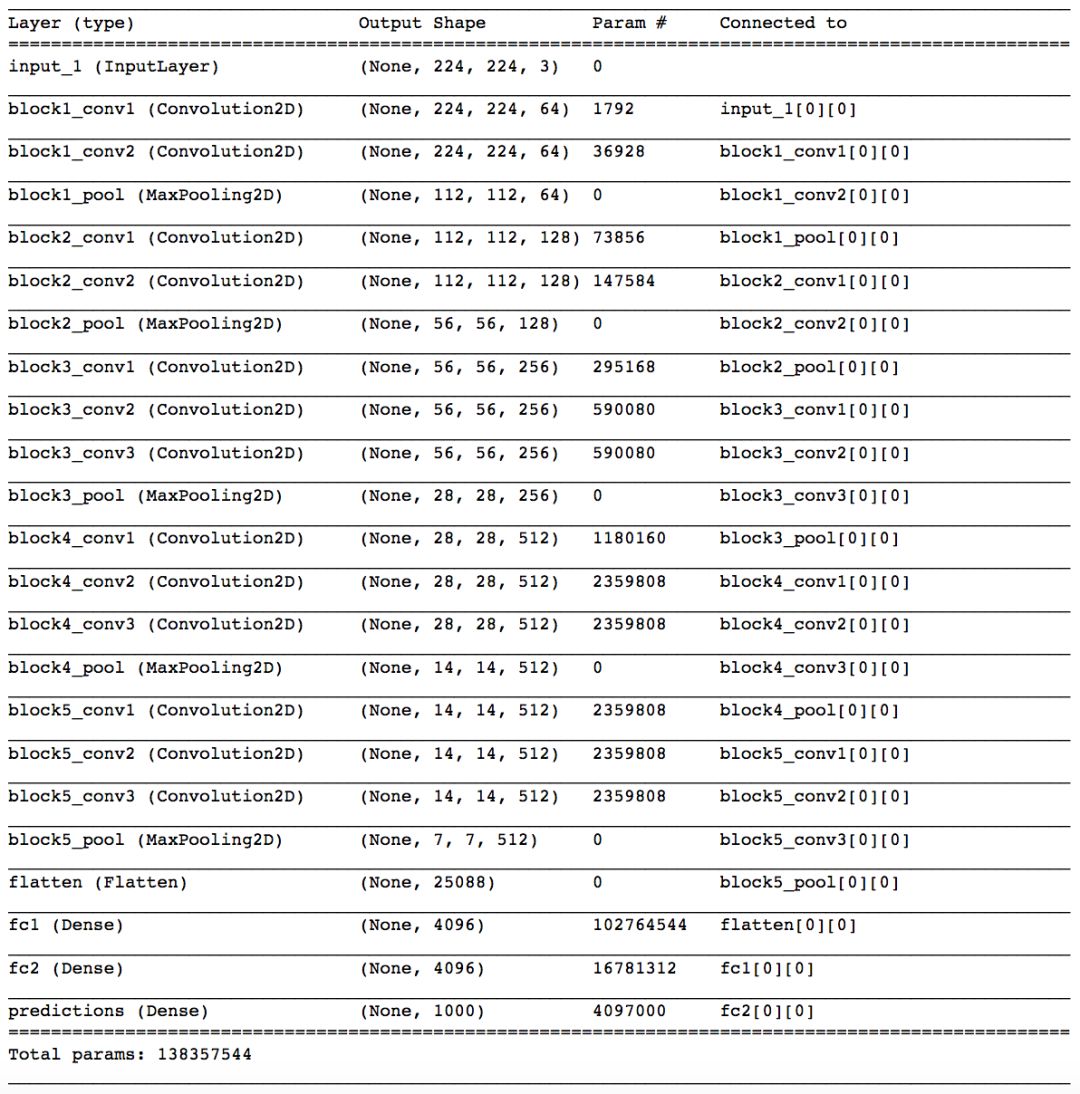
You will notice that there are 5 convolutional modules (two to three convolutional layers, followed by a max pooling layer). Next, flatten the last maximum pooling layer, followed by three dense layers. Note that most of the parameters of the model belong to the fully connected layer!
You can probably imagine that such an architecture has the risk of overfitting the training data set. In practice, the dropout layer is used to avoid overfitting.
Global average pooling
In recent years, people have begun to use the global average pooling (GAP) layer to minimize the overfitting effect by reducing the number of model parameters. Similar to the maximum pooling layer, the GAP layer can be used to reduce the spatial dimension of the three-dimensional tensor. However, the dimensionality reduction of the GAP layer is more radical, and a tensor of h × w × d will be reduced to 1 × 1 × d. The GAP layer maps each h × w feature to a single number by averaging.
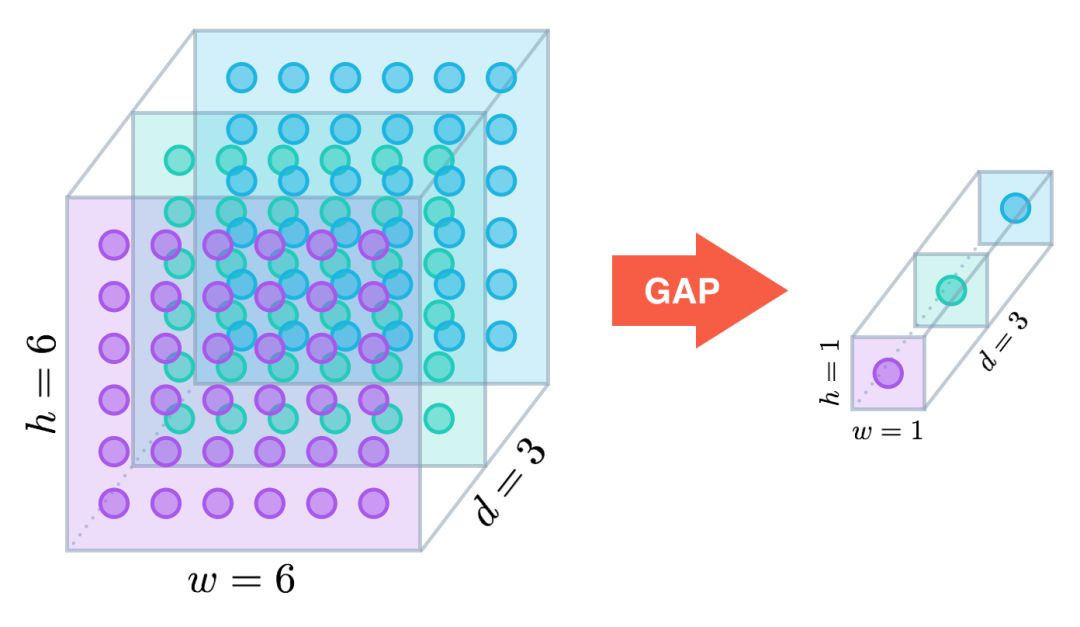
In the Network in Network architecture where the GAP layer was first proposed, the output of the last maximum pooling layer is passed to the GAP layer, and the GAP layer generates a vector, and each item of the vector represents a category in the classification task. Then apply the softmax activation function to generate the predicted probability of each category. If you plan to refer to the original paper (arXiv:1312.4400), I especially recommend that you read the next section 3.2 "Global Average Pooling".
The ResNet-50 model is not so radical; it does not completely remove the dense layer, but adds a dense layer with a softmax activation function after the GAP layer to generate predictive classification.
target setting
In mid-2016, MIT researchers showed that a CNN (GAP-CNN) with a GAP layer trained for classification tasks can also be used for target location. In other words, GAP-CNN not only tells us what the target is contained in the image, it can also tell us where the target is in the image, and we don't need to do anything extra for it! The localization is expressed as a heat map (classification activation map), in which the color coding scheme indicates the relatively important areas of GAP-CNN for target recognition tasks.
I explored the positioning capabilities of the pre-trained ResNet-50 model based on the paper by Bolei Zhou et al. (arXiv:1512.04150) (see GitHub: alexisbcook/ResNetCAM-keras for the code). The main idea is that each activation map of the last layer before the GAP layer plays a role in the pattern of different positions in the decoded image. We only need to convert these detected patterns into detected targets to get the classification activation map of each image.
Each node in the GAP layer corresponds to a different activation map, and the weights connecting the GAP layer and the final dense layer encode the contribution of each activation map to the prediction target classification. The contribution of each detected mode in the activation map (the detected mode that is more important for predicting the target classification gets more weight) is accumulated, and the classification activation map is obtained.
How the code works
Run the following code to view the architecture of ResNet-50:
python -c'from keras.applications.resnet50 import ResNet50; ResNet50().summary()'
The output is as follows:
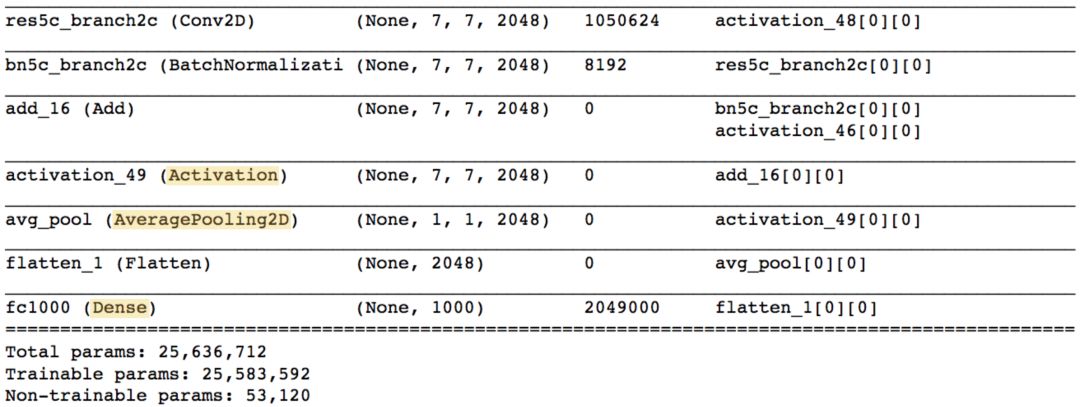
Note that, unlike the VGG-16 model, not most of the trainable parameters are located in the fully connected layer at the top of the network.
The Activation, AveragePooling2D, and Dense layers at the end of the network are the ones we are most interested in (the highlighted part in the figure above). In fact, the AveragePooling2D layer is a GAP layer!
We start from the Activation layer. This layer contains 2048 7 × 7-dimensional activation maps. Let us denote the k-th activation map by fk, where k ∈ {1,...,2048}.
The next AceragePooling2D layer, which is the GAP layer, reduces the output size of the previous layer to (1,1,2048) by taking the average of each activation map. The next Flatten layer is just flattening the input, without causing any changes to the information contained in the previous GAP layer.
Each target category predicted by ResNet-50 corresponds to each node of the final Dense layer, and each node is connected to each node of the previous Flatten layer. Let us use wk to denote the weight that connects the k-th node of the Flatten layer with the output node of the corresponding predicted image category.
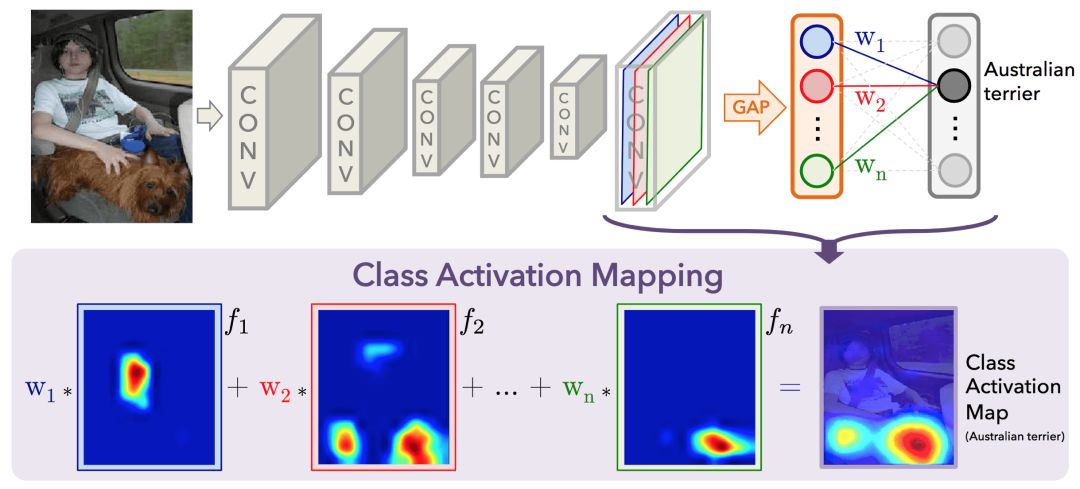
Then, in order to get the classification activation map, we only need to calculate:
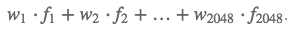
We can draw these classification activation maps on selected images to explore the positioning capabilities of ResNet-50. In order to facilitate the comparison with the original image, we applied bilinear upsampling to change the size of the activation map to 224 × 224.
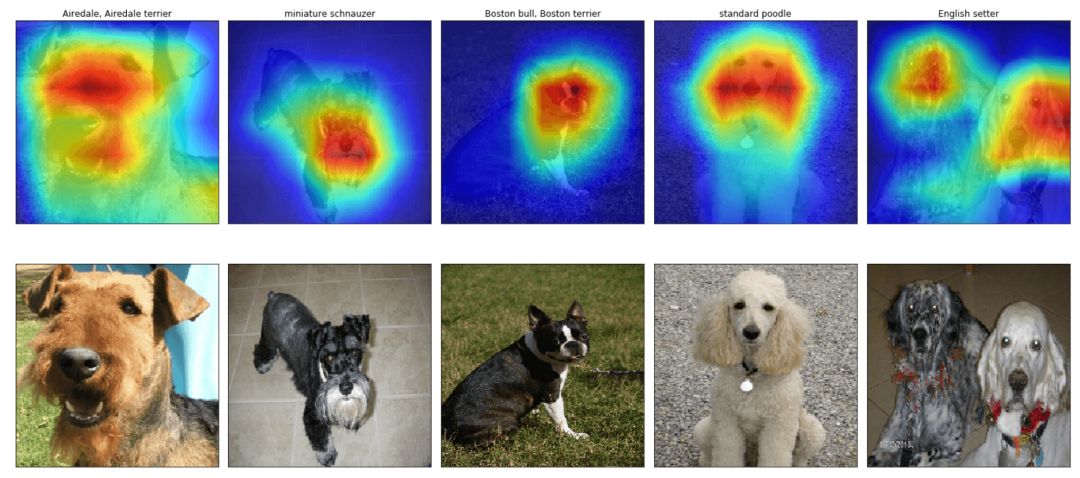
If you want to apply these codes to your own targeting problem, you can visit GitHub: https://github.com/alexisbcook/ResNetCAM-keras
liquid keychain wholesale,liquid keychain toy,moving liquid keychain,liquid keychain diy,custom liquid keychain,liquid keychain manufacturer
Shenzhen Konchang Electronic Technology Co.,Ltd , https://www.konchangs.com