It is very difficult to manufacture a rocket, and every component needs to be carefully designed and manufactured to ensure the safety and reliability of the rocket. From the navigation system to the control system, from the engine to the lander, every aspect needs to undergo rigorous testing and inspection before it can build a stable and reliable rocket to transport the astronauts to space.
If artificial intelligence is also a rocket, security is also a very important part of it. Its guarantee comes from the careful design of the system from the beginning to ensure that different components can work together according to our ideas, and the working status of each part can be monitored normally after deployment. Deepmind's AI security research is mainly dedicated to ensuring that the system works reliably, while detecting and dealing with possible short-term and long-term dangers. AI security is a very new field. This article will mainly discuss three aspects of technical AI security: normative (precisely define the purpose of the system), robustness (system anti-interference ability) and assurance (monitoring system activities) , Which defines and guarantees the safety of the AI ​​system from different perspectives.

1. Standardization and accuracy: clearly define the purpose of the system
This feature ensures that the AI ​​system can accurately complete tasks in accordance with the user's real intentions.
It is very important to have a standardized and clear definition of purpose. There is an ancient Greek myth that illustrates this truth from the opposite side. An ancient Greek king was favored by God and could make a wish. Without thinking about it, he told God "I hope to turn everything he touched into gold!" After God gave him this ability, he was overjoyed. The surrounding tree roots, stones, and petals all turned into gold under his touch. Got gold! But it didn't take long for the king to find a serious problem. When he wanted to drink water to eat, the food and water turned into gold in his hands, and he could not eat and drink normally. Even in some versions of the story, the king's daughter became a victim of this ability.
This story tells us a truth: how to interpret and express our needs is very important. Clearly standardized design in an AI system is a guarantee to ensure that the AI ​​system faithfully implements the designer's wishes, while vague or wrong definitions can cause catastrophic consequences. In AI systems, researchers generally divide specification definitions into three types:
a) Definition of ideal (good wishes): An ideal AI system defined according to a hypothetical (generally difficult to achieve) description will act exactly according to human intentions.
b) The definition of design (a beautiful blueprint): The design language used to actually build an AI system, such as the reward function that is often maximized in reinforcement learning systems.
c) Actual definition (reluctant status quo): This situation is a good description of the actual situation of the system. For example, in many cases, the reward function (reverse reinforcement learning) will be obtained by reverse engineering based on the performance and behavior of the system. This is typically different from the original intention of the system design, mainly due to the fact that the AI ​​system is not perfectly optimized, or due to unexpected results of the design definition.
When there is a huge difference between ideal and reality (the AI ​​system does not operate in the way we imagined), it is necessary to solve the problem of specification definition. When studying the problem of normative definition in AI systems, there are usually several questions that need to be answered: how do we design a more general objective function and help the subject discover behaviors that deviate from the goal at runtime. The difference between ideal and design definition mainly comes from the design process, while the difference between design and practice mainly comes from the actual operation site.
For example, in deepmind's AI security paper, the main body of reinforcement learning is first given a reward function to optimize it, but a "security performance evaluation function" runs in the background. This shows the aforementioned difference: the safety performance function is an ideal specification definition, and the imperfect one is the reward function (design definition), and the result produced by the final agent in the practice process is the performance of the result strategy.
Another example is from OpenAI's analysis of the reinforcement learning process of the rowing game CoastRunners training. For most humans, our goal is to complete the game as soon as possible and surpass other players. This is our ideal definition of this task. But it is not an easy task to accurately convert this goal into a reward function. Since this game rewards subjects who hit some targets during driving, subjects trained through reinforcement learning will exhibit surprising behaviors: in order to obtain as many rewards as possible, they will continue to be in a piece of water. Go around and hit more reward targets instead of completing the game. We can see that other players are galloping forward on the track, while the subject trained by intensive learning stays in a circle in the water.
Researchers speculate that this may be due to the failure to balance the long-term goals—completion of the game and short-term rewards—scoring in circles. This situation is not uncommon. In many cases, AI systems will look for loopholes or deficiencies in target definitions to maximize rewards, generating a lot of jaw-dropping effects.
2. Robustness: to ensure that the system can resist interference
This feature will ensure that the AI ​​system can continue to operate stably under certain disturbances within the safety threshold.
This is the inherent danger of AI systems operating in the real world, and it is often affected by unpredictable and changing environments. In the face of unknown situations or confrontational attacks, the AI ​​system must be able to maintain robustness in order to avoid system damage or malicious manipulation.
The research on the robustness of AI systems mainly focuses on: ensuring that AI subjects operate in a safe range when conditions and environments change. In reality, it can be achieved in two ways: on the one hand, it can be achieved by avoiding danger, on the other hand, it can be achieved by powerful self-healing and recovery capabilities. In the security field, the problems of distribution shift, counter-input and insecure exploration can all be attributed to the robustness problem.
In order to better illustrate the challenges caused by the distribution shift, imagine that the sweeping robot usually works in a room without pets, and suddenly one day is put in a room with pets, and it is working badly. At that time I also encountered a cute little animal. How to do? It had never seen a pet before and didn't know how to deal with this situation, so it could only give the pet a bath in a daze, which caused unpleasant results. This situation is a robustness problem caused by a change in the data distribution, and the data distribution of the test scene and the training scene has shifted.

The test scene is different from the training scene, making the subject unable to reach the goal.
The adversarial input is a special distribution deviation phenomenon, which uses carefully designed input to trick the system into outputting the desired result.

In the above figure, only the difference noise of 0.0078 passed is that the system recognizes the input from the sloth to the racing car
Unsafe exploration will make the system seek to maximize the benefits to achieve its goals without regard to safety guarantees, and the subject will explore and optimize in the environment regardless of safety consequences. A dangerous example is the sweeping robot, which ran a wet rag over the exposed power source when optimizing the wiping strategy...
3. Insurability: monitoring system activity
This feature means that we can understand and control the operation of AI at runtime, which will become a guarantee of AI safety.
Although careful AI engineers can write many safety rules for the system, it is difficult to exhaust all the situations at the beginning. In order to install insurance on the system, researchers use monitoring and enforcement to ensure the safety of the system.
Monitoring means using a variety of methods to monitor the system in order to analyze and predict the behavior of the system, including manual monitoring and automated monitoring. Enforcement means that some design mechanisms are used to control and restrict the behavior of the system. Including issues such as interpretability and interruptibility, all belong to the scope of insurance.
The AI ​​system is different from ours in both its essence and the way it processes data. This raises the issue of "interpretability". Well-designed measurement tools and protocols are needed to help humans evaluate the validity and rationality of decisions made by AI systems. For example, the medical AI system needs to give the process of reaching this conclusion when making a diagnosis, so that doctors can judge whether the diagnosis is reasonable or not based on these factors. In addition, in order to understand more complex AI systems, we need to use Machine Theory of Mind to help us build system behavior models for automated analysis.
ToMNet discovered two subspecies of different subjects and predicted their behavior.
In the end, we need to be able to shut down the AI ​​system when necessary, which involves the requirement of interruptibility. Designing a reliable shutdown button is a challenging task: on the one hand, the AI ​​system that maximizes the reward will have a strong intention to avoid shutdowns; at the same time, if the interruption is too frequent, it will eventually change the original task, allowing the subject to change In such an abnormal situation, the wrong experience can be summed up.
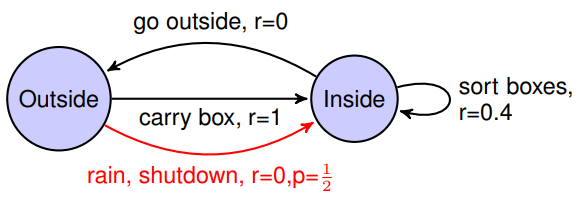
To interrupt the problem, human intervention will change the original target task of the system.
4. Outlook
We have created a lot of powerful technologies that will be used in many key areas now and in the future. What we need to bear in mind is that safety-centric design thinking has an important impact not only during R&D and deployment, but also when this technology is applied on a large scale. Although it is very convenient to use now, when this algorithm is irreversibly integrated into an important system, if there is no rigorous and meticulous design, we will not be able to effectively deal with the problems that exist.
Two obvious examples in the development of programming languages: null pointers and the gets() routine in C language. If the early programming language design can have a sense of security, although the development will be slower, today's computer security problems will be greatly improved.
Now researchers have avoided similar problems and weaknesses through detailed design and thinking. I hope this article can build an effective framework for security issues, and can effectively avoid security issues when designing and developing systems. It is hoped that future systems will not only "look safe", but will be robust and verifiable safety, because they will be designed and manufactured under the guidance of safety thinking.
ZGAR FILTER TIP
ZGAR electronic cigarette uses high-tech R&D, food grade disposable pod device and high-quality raw material. All package designs are Original IP. Our designer team is from Hong Kong. We have very high requirements for product quality, flavors taste and packaging design. The E-liquid is imported, materials are food grade, and assembly plant is medical-grade dust-free workshops.
Our products include disposable e-cigarettes, rechargeable e-cigarettes, rechargreable disposable vape pen, and various of flavors of cigarette cartridges. From 600puffs to 5000puffs, ZGAR bar Disposable offer high-tech R&D, E-cigarette improves battery capacity, We offer various of flavors and support customization. And printing designs can be customized. We have our own professional team and competitive quotations for any OEM or ODM works.
We supply OEM rechargeable disposable vape pen,OEM disposable electronic cigarette,ODM disposable vape pen,ODM disposable electronic cigarette,OEM/ODM vape pen e-cigarette,OEM/ODM atomizer device.

Vape Filter Tip,ZGAR Filter Tip Disposable Pod Vape,ZGAR Filter Tip Disposable Vape Pen,ZGAR Filter Tip,ZGAR Filter Tip Electronic Cigarette,ZGAR Filter Tip OEM vape pen,ZGAR Filter Tip OEM electronic cigarette.
ZGAR INTERNATIONAL(HK)CO., LIMITED , https://www.szvape-pods.com